
Bem Vindo(a)!
Por Felipe Lamounier, Minas Gerais, Brasil – powered by 🙂My Easy B.I.
Este post tem como objetivo fazer uma rápida introdução ao Apache Airflow, uma ferramenta de orquestração de carga projetada para programar, organizar e monitorar fluxos de trabalho complexos de Big Data. Utilizando o conceito de “DAGs” (Directed Acyclic Graphs), o Airflow permite que engenheiros de dados e desenvolvedores definam, automatizem e monitorem pipelines de dados de forma flexível e escalável. Com uma interface de usuário intuitiva, extensibilidade através de plugins, e a capacidade de integrar-se com uma ampla variedade de sistemas e serviços através de operadores e hooks, o Airflow se tornou uma ferramenta essencial para orquestração de tarefas em ambientes de dados modernos, suportando tudo desde simples tarefas de transferência de dados até workflows analíticos complexos.
📑 Índice:
- Introdução
- Como Airflow funciona
- Operators
- Estrutura de uma DAG
- Trigger Rule
- Principais Argumentos de uma DAG
- Task Group
- Xcom: troca de dados entre tasks
- Variáveis
- Pools
- Branchs
- Datasets (Data-aware scheduling)
- Sensors
- DAG que executa DAG
- Envio de E-mail
- Hooks
- Executors
- Melhores Práticas
- Conclusão
Introdução
O Apache Airflow é uma plataforma de código aberto usada para programar, coordenar e monitorar fluxos de trabalho. É amplamente utilizado para gerenciar fluxos de trabalho relacionados a processamento de dados e automação de tarefas. Em outras palavras, o Airflow é um orquestrador de cargas, portanto não processa dados, ele coordena o processamento.
O Apache Airflow é desenvolvido em Python e é extensível
Conceitos Básicos:
- DAGs (Directed Acyclic Graphs): São conjuntos de tarefas organizadas de forma que reflitam suas dependências e sequência de execução. Cada DAG define um fluxo de trabalho.
- Um DAG é definido em um script Python. Você precisa importar as classes necessárias, definir os operadores e suas dependências.
- Operadores: São as tarefas individuais que são executadas como parte de um DAG. Existem diferentes tipos de operadores para diferentes tipos de tarefas, como
BashOperatorpara tarefas de shell ePythonOperatorpara tarefas em Python. - Tasks: São as instâncias dos operadores. Uma tarefa representa uma unidade de trabalho dentro de um DAG.
- Scheduler: É o componente que agenda a execução dos DAGs com base no tempo ou em outras dependências.
- Executor: É o mecanismo que executa as tarefas. O Airflow oferece vários executores, como o
SequentialExecutor,LocalExecutoreCeleryExecutor. - Web Server: Interface gráfica do usuário que permite aos usuários visualizar o progresso e o estado dos DAGs e das tarefas.
Arquitetura Airflow:

Como Airflow funciona
O princípio básico do Airflow são as DAG’s.
- DAG é um pipeline do Airflow, que define o que este pipeline irá fazer
- Composto por Operadores/Tasks
- DAG é um script python
- Não precisa ter a lógica (classe externa)
- Um mesmo script pode ter múltiplas DAGs
- Uma DAG pode ter uma ou mais tasks
- Tasks possuem dependência

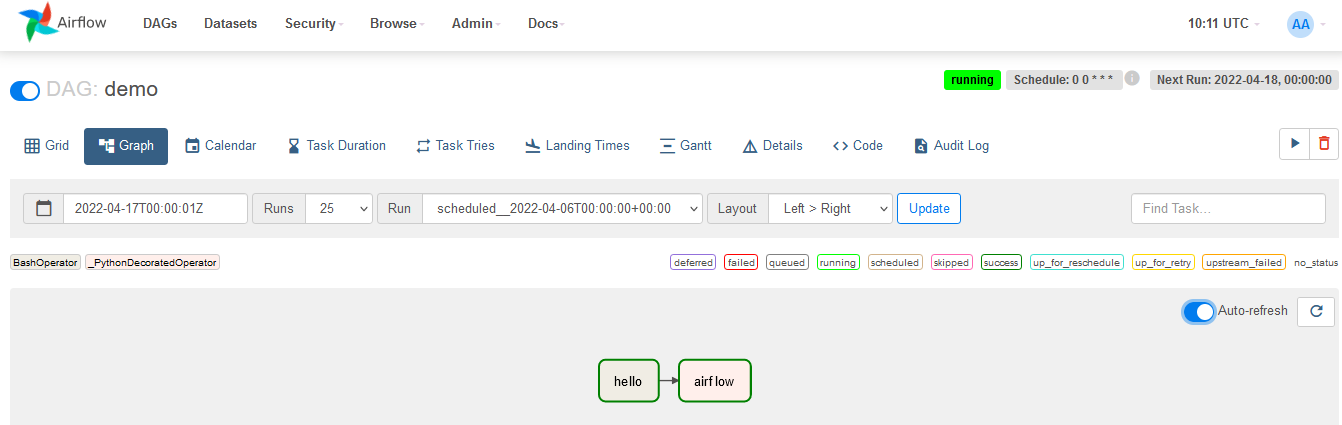
Exemplo de código python de uma DAG:
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
from airflow.operators.bash import BashOperator
# A DAG represents a workflow, a collection of tasks
with DAG(dag_id="demo", start_date=datetime(2022, 1, 1), schedule="0 0 * * *") as dag:
# Tasks are represented as operators
hello = BashOperator(task_id="hello", bash_command="echo hello")
@task()
def airflow():
print("airflow")
# Set dependencies between tasks
hello >> airflow()Explicação do código acima:
- Importações iniciais: O código começa importando o necessário do módulo
datetimee algumas partes específicas do Apache Airflow - Definição da DAG: Uma DAG é criada com o identificador “demo”, com uma data de início em 1º de janeiro de 2022, e uma programação definida para rodar à meia-noite todos os dias (
"0 0 * * *"). - Definição das tarefas: Uma tarefa chamada “hello” é criada usando
BashOperator. Isso significa que ela executará um comando no Bash (um tipo de terminal ou shell do Unix/Linux) que simplesmente imprime “hello”. - Outra tarefa é definida como uma função chamada
airflow, que apenas imprime “airflow” quando executada. - Estabelecendo dependências: No final do código, há uma linha
hello >> airflow(), que estabelece a ordem das tarefas. Isso significa que a tarefahelloprecisa ser concluída antes que a tarefaairflowpossa começar.
Em resumo, este código cria um fluxo de trabalho no Airflow que, todos os dias à meia-noite, primeiro imprime “hello” e depois “airflow”.
Operators
- Algo a ser feito no pipeline
- Uma vez instanciado, é uma tarefa
Classe dos Operadores:
- Sensor: monitorar arquivo, pasta ou banco de dados
- Transfer: transferir dados
- Action: basch, Python, etc
Tipos de Operadores:
- BashOperator: executa um comando de shell ou script
- PythonOperator: executa uma função Python
- DummyOperator: não faz nada e é útil para fins de organização
- EmailOperator: envia um e-mail
- SQLOperator: executa uma consulta SQL
- FileSensor: aguarda até que um arquivo seja criado ou modificado
- TriggerDagRunOperator: executa uma DAG de outra DAG
Estrutura de uma DAG
Uma DAG é composta basicamente por Módulos, Dag, Tasks e Precedência/Execução:

A DAG acima é um exemplo básico com o intuito de mostrar a estrutura de uma DAG. Abaixo a explicação do código:
- Importações: O código começa importando as classes e funções necessárias de Airflow e da biblioteca
datetime. Essas importações são essenciais para criar a DAG e definir tarefas que executam comandos do bash. - Criação da DAG: Você definiu uma DAG chamada ‘exemplo_dag’, que não tem agendamento fixo (
schedule_interval=None) e começa a partir de 5 de março de 2023.catchup=Falseevita a execução de instâncias retroativas da DAG. - Definição de Tarefas: Três tarefas foram criadas (
task1,task2,task3), todas usandoBashOperatorpara executar o comandosleep 5. Isso faz cada tarefa pausar por 5 segundos. - Definição de Dependências: As tarefas são organizadas em sequência, onde
task1executa primeiro, seguida portask2, e entãotask3.
Trigger Rule
Define a lógica que determina quando uma tarefa específica deve ser executada, com base no estado das tarefas das quais ela depende. Por padrão, uma tarefa no Airflow é disparada quando todas as suas tarefas antecessoras são bem-sucedidas. Essa é a regra “all_success”. No entanto, você pode definir outras regras de disparo para lidar com diferentes cenários e necessidades de dependência entre tarefas. Aqui estão algumas das regras de disparo disponíveis:
- all_success: É a regra padrão. A tarefa será executada somente se todas as tarefas antecessoras forem bem-sucedidas.
- all_failed: A tarefa será executada somente se todas as tarefas antecessoras falharem.
- all_done: A tarefa é executada quando todas as tarefas anteriores foram concluídas, independentemente do status.
- one_failed: A tarefa será executada se pelo menos uma das tarefas antecessoras falhar.
- one_success: A tarefa será executada se pelo menos uma das tarefas antecessoras for bem-sucedida.
- none_failed: A tarefa será executada se nenhuma das tarefas antecessoras falhar, ou seja, se todas forem bem-sucedidas ou algumas ficarem em estado “skipped”.
- none_skipped: A tarefa será executada se nenhuma das tarefas antecessoras for pulada.
- dummy: A tarefa será executada independentemente do estado das tarefas antecessoras. É útil em casos onde a tarefa não tem dependências reais.
Essas regras oferecem flexibilidade para definir lógicas complexas de dependência entre as tarefas em um DAG, permitindo que você construa workflows robustos e resilientes a falhas. Para definir uma regra de disparo diferente da padrão, você pode usar o parâmetro trigger_rule ao definir uma tarefa.
Código de exemplo:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
dag = DAG('triggerdag2', description="Trigger",
schedule_interval=None,start_date=datetime(2023,3,5),
catchup=False)
task1 = BashOperator(task_id="tsk1",bash_command="exit 1",dag=dag )
task2 = BashOperator(task_id="tsk2",bash_command="sleep 5",dag=dag )
task3 = BashOperator(task_id="tsk3",bash_command="sleep 5",dag=dag,
trigger_rule='one_failed' )
[task1,task2] >> task3Explicação do código:
- Importações e Definição da DAG:
- Importa-se as classes necessárias do Airflow e
datetime. - Cria-se uma DAG chamada ‘triggerdag2’, que não é executada automaticamente em intervalos regulares (
schedule_interval=None) e tem início em 5 de março de 2023. O parâmetrocatchup=Falseimpede execuções retroativas.
- Importa-se as classes necessárias do Airflow e
- Criação das Tarefas:
task1: UsaBashOperatorpara executar o comandoexit 1, que retorna um erro.task2: Executasleep 5, pausando por 5 segundos sem erro.task3: Também pausa por 5 segundos, mas possui a regra de disparoone_failed, indicando que será executada se pelo menos uma das tarefas anteriores falhar.
- Dependências:
- As tarefas
task1etask2são configuradas para executar antes datask3. O operador>>define essa sequência. - A
task3só será executada setask1outask2falhar, devido aotrigger_rule='one_failed'.
- As tarefas
Em resumo, esta DAG executa duas tarefas em paralelo (task1 e task2). Independentemente do sucesso de task2, se task1 falhar, task3 será acionada devido à sua regra de disparo especificada.
Principais Argumentos de uma DAG
Os argumentos de uma DAG no Apache Airflow definem suas propriedades e comportamento dentro do ecossistema Airflow. Quando você cria uma instância de DAG, pode passar vários parâmetros para configurá-la de acordo com suas necessidades
- dag_id: Uma string única que identifica a DAG dentro do Airflow. É o nome que será exibido na interface do usuário.
- description: Uma string que fornece uma descrição sobre o que a DAG faz, ajudando outros usuários do Airflow a entender seu propósito.
- schedule_interval: Define com que frequência a DAG é acionada. Pode ser uma expressão cron (como
'0 5 * * *'para todos os dias às 5h00), umtimedeltaobject (por exemplo,datetime.timedelta(days=1)para diariamente), ouNonepara indicar que a DAG não deve ser agendada. - start_date: Um objeto
datetimeque define quando a DAG deve começar a ser agendada. Nenhuma execução será agendada antes dessa data. - end_date: Um objeto
datetimeopcional que, se definido, indica quando a DAG não deve mais ser agendada. - default_args: Um dicionário de argumentos que serão aplicados por padrão a todas as tarefas da DAG. Pode incluir coisas como
owner,retries,retry_delay,email_on_failure,email_on_retry, etc. - catchup: Um valor booleano que, quando
False, indica que o Airflow não deve executar execuções para instâncias de dags que não foram executadas no passado (antes da data atual). SeTrue, o Airflow agendará todas as execuções que não aconteceram desde astart_date. - max_active_runs: O número máximo de execuções ativas permitidas para esta DAG. Previne o Airflow de executar muitas instâncias da DAG ao mesmo tempo.
- tags: Uma lista de strings que servem como tags para a DAG. Isso pode ajudar na organização e na filtragem das DAGs na interface do usuário.
- concurrency: O número máximo de tarefas que podem ser executadas simultaneamente dentro desta DAG.
- on_success_callback / on_failure_callback: Funções de callback que podem ser chamadas quando a DAG é bem-sucedida ou encontra falha, respectivamente.
- doc_md: Descrição da DAG em Markdown, que pode incluir documentação mais extensa do que o campo
descriptionpermite. - default_view: Define a visualização padrão para a DAG na interface do usuário do Airflow. Os valores possíveis incluem ‘tree’, ‘graph’, ‘calendar’, ‘gantt’, ‘duration’, etc. Isso determina qual aba é mostrada por padrão quando você acessa uma DAG na interface do usuário.
- concurrency: Um limite para o número de tarefas que podem ser executadas simultaneamente em uma DAG. Isso ajuda a controlar a carga no executor e evitar sobrecarga nos recursos.
- depends_on_past: Um booleano que, quando definido como
True, faz com que as tarefas de uma DAG dependam do sucesso da mesma tarefa na execução anterior. Isso é útil para garantir que as tarefas sejam executadas em ordem e que uma falha tenha que ser corrigida antes que a tarefa seja executada novamente. - email: Uma lista de endereços de e-mail para os quais o Airflow enviará notificações. Esses e-mails podem ser notificações sobre falhas, tentativas ou outras informações relevantes da execução da DAG.
- email_on_failure: Um booleano que, quando definido como
True, faz com que o Airflow envie e-mails para os endereços listados ememailquando a DAG falha. - email_on_retry: Semelhante ao
email_on_failure, mas os e-mails são enviados em caso de novas tentativas de execução de tarefas, não apenas falhas. - retries: Um inteiro que define o número máximo de vezes que uma tarefa será reexecutada em caso de falha. O Airflow tentará executar novamente a tarefa esse número de vezes antes de considerá-la como falhada definitivamente.
- retry_delay: Define o intervalo de tempo entre tentativas de execução de uma tarefa. É um objeto
timedelta, que permite especificar dias, horas, minutos, segundos, etc.
default_args
Permite definir argumentos padrão que serão aplicados a todas as tarefas dentro da DAG. Usar default_args ajuda a evitar repetições, tornando o código mais limpo e fácil de manter, pois você não precisa especificar o mesmo argumento para cada tarefa individualmente.

default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 1, 1),
'email': ['example@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}schedule_interval
O schedule_interval é um argumento crucial em uma DAG do Apache Airflow, pois define com que frequência a DAG deve ser executada. Esse argumento pode aceitar diferentes formatos de valores, proporcionando flexibilidade para agendar execuções conforme a necessidade.
- Cron Expressions: Você pode usar uma expressão cron para definir o
schedule_interval. Por exemplo,"0 12 * * *"agendaria a DAG para executar todos os dias ao meio-dia.- As expressões cron são poderosas e permitem agendamentos complexos, mas podem ser um pouco difíceis de interpretar se você não estiver familiarizado com sua sintaxe.
- Preset Timedeltas: O Airflow oferece algumas strings predefinidas que representam intervalos comuns, como
- None
@once@daily@hourly@weekly@monthly@yearly- Por exemplo, usar
'@daily'é equivalente a usar uma expressão cron de"0 0 * * *"para executar a DAG uma vez por dia à meia-noite.
- Datetime Timedelta: Você pode definir o
schedule_intervalcomo um objetodatetime.timedelta, o que oferece flexibilidade para especificar quase qualquer duração de intervalo. Por exemplo,datetime.timedelta(days=1)agendaria a DAG para rodar uma vez a cada 24 horas. - None: Definir
schedule_interval=Nonesignifica que a DAG não será agendada automaticamente. Você precisaria acioná-la manualmente ou desenvolver algum outro mecanismo para sua execução.
catchup
O parâmetro catchup em uma DAG do Apache Airflow determina se o Airflow deve executar instâncias retroativas para os intervalos de programação que ocorreram no passado, mas não foram executados desde a start_date da DAG. Quando catchup está definido como True (o padrão), o Airflow agendará e executará essas instâncias passadas automaticamente ao ativar a DAG. Se definido como False, o Airflow ignorará os intervalos passados e só executará a DAG para os intervalos de programação futuros, a partir do momento em que a DAG é ativada. Essa configuração é útil para controlar o comportamento da DAG em relação ao processamento de dados históricos ou ao iniciar pipelines de dados sem a necessidade de processar dados anteriores à ativação da DAG.
Task Group
O Task Group no Apache Airflow é um recurso que permite agrupar várias tarefas em uma unidade lógica dentro do DAG. Isso ajuda a organizar melhor o código e a visualização no Airflow UI, tornando mais fácil entender e gerenciar fluxos de trabalho complexos. Aqui estão alguns pontos-chave sobre o Task Group:
- Organização: O Task Group ajuda a estruturar melhor um DAG, especialmente quando ele tem muitas tarefas. Ao agrupar tarefas relacionadas, você pode reduzir a complexidade visual e facilitar a compreensão do fluxo de trabalho.
- Encapsulamento: Tarefas dentro de um grupo são tratadas como uma única unidade na interface gráfica do usuário do Airflow. Isso significa que você pode expandir e recolher grupos para visualizar o nível de detalhes desejado, o que é especialmente útil para DAGs com um grande número de tarefas.
- Reutilização: Task Groups também promovem a reutilização de código. Você pode definir um grupo de tarefas como um módulo e reutilizá-lo em diferentes partes do seu DAG ou em DAGs diferentes, mantendo o código DRY (Don’t Repeat Yourself).
- Implementação: Para criar um Task Group no seu código Airflow, você pode usar o contexto
with TaskGroup("group_id") as group:. Todas as tarefas definidas dentro deste bloco pertencerão ao grupo especificado. - Aninhamento: Você pode aninhar Task Groups dentro de outros Task Groups para criar hierarquias complexas e bem organizadas, permitindo uma estrutura ainda mais modular e compreensível para seus DAGs.
Em resumo, Task Groups são extremamente úteis para melhorar a organização, leitura e manutenção de seus DAGs, especialmente à medida que eles crescem em complexidade e tamanho.
Exemplo:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
from airflow.utils.task_group import TaskGroup
dag = DAG('daggroup', description="Group",
schedule_interval=None,start_date=datetime(2023,3,5),
catchup=False)
task1 = BashOperator(task_id="tsk1",bash_command="sleep 5",dag=dag )
task2 = BashOperator(task_id="tsk2",bash_command="sleep 5",dag=dag )
task3 = BashOperator(task_id="tsk3",bash_command="sleep 5",dag=dag )
task4 = BashOperator(task_id="tsk4",bash_command="sleep 5",dag=dag )
task5 = BashOperator(task_id="tsk5",bash_command="sleep 5",dag=dag )
task6 = BashOperator(task_id="tsk6",bash_command="sleep 5",dag=dag )
tsk_group = TaskGroup("tsk_group", dag=dag)
task7 = BashOperator(task_id="tsk7",bash_command="sleep 5",dag=dag,task_group=tsk_group)
task8 = BashOperator(task_id="tsk8",bash_command="sleep 5",dag=dag,task_group=tsk_group )
task9 = BashOperator(task_id="tsk9",bash_command="sleep 5",dag=dag,
trigger_rule='one_failed',task_group=tsk_group )
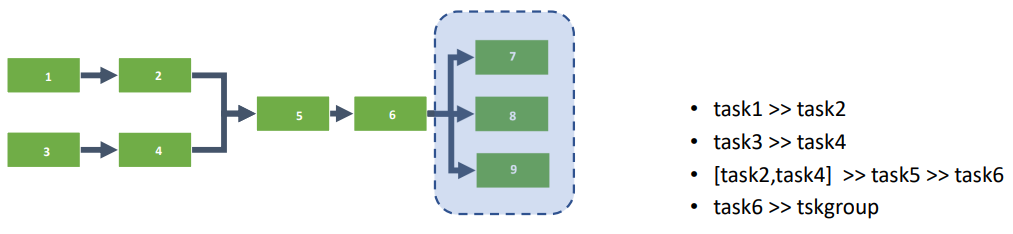
task1 >> task2
task3 >> task4
[task2,task4] >> task5 >> task6
task6 >> tsk_groupExplicação do código:
- Importações: O código importa as classes necessárias do Airflow e o módulo
datetimepara definir datas. - Definição da DAG: A DAG chamada ‘daggroup’ é criada sem um intervalo de agendamento (
schedule_interval=None), inicia em 5 de março de 2023, e evita a execução de instâncias para períodos anteriores (catchup=False). - Definição de Tarefas Individuais: São criadas seis tarefas (
task1atask6), todas usandoBashOperatorpara executar o comandosleep 5. Essas tarefas não fazem parte de nenhum grupo de tarefas e têm dependências definidas entre elas:task1é seguida portask2.task3é seguida portask4.task5começa após a conclusão detask2etask4e é seguida portask6.
- Criação do Task Group: Um grupo de tarefas é criado usando
TaskGroupe nomeado “tsk_group”. Este grupo é associado à mesma DAG (dag=dag). - Definição de Tarefas dentro do Task Group: Dentro do grupo ‘tsk_group’, são definidas três tarefas adicionais (
task7,task8,task9) também com oBashOperator. Essas tarefas executam o mesmo comandosleep 5e estão agrupadas para que sejam visualizadas juntas na interface do Airflow. - Regra de Gatilho e Dependências: A
task9dentro do grupo tem umatrigger_rule='one_failed', o que significa que ela só será executada se pelo menos uma das outras tarefas no grupo falhar. - Dependências entre Grupos e Tarefas: Após a conclusão de
task6, o grupo de tarefas ‘tsk_group’ é executado. Dentro do grupo, as tarefastask7etask8não têm dependências definidas explicitamente no código fornecido, então elas assumirão o padrão de execução paralela, enquantotask9depende do resultado de outras tarefas dentro do grupo.
Xcom: troca de dados entre tasks
XCom, abreviação de “Cross-Communication”, é um recurso do Apache Airflow que permite que tarefas troquem mensagens ou dados entre si. XComs proporcionam um meio para tarefas dentro de uma DAG passarem informações como valores de retorno, status ou dados auxiliares, permitindo interações mais complexas entre tarefas em um fluxo de trabalho. Aqui estão os pontos-chave sobre XComs no Airflow:
- Armazenamento: XComs armazenam dados no banco de dados do Airflow, o que significa que as informações podem ser persistentes e recuperadas em qualquer ponto do tempo de execução da DAG.
- Uso: Uma tarefa pode “empurrar” dados para XCom usando o método
xcom_push, e outra tarefa pode posteriormente “puxar” esses dados comxcom_pull. Por exemplo, uma tarefa pode extrair dados de uma fonte, armazená-los como XCom, e outra tarefa subsequente pode recuperar esses dados para processamento adicional ou análise. - Escopo: O escopo de uma XCom é geralmente limitado à DAG em que é criada, garantindo que os dados não sejam acidentalmente compartilhados entre fluxos de trabalho não relacionados.
- Interface do Usuário: O Airflow UI exibe as XComs, permitindo que os usuários vejam quais dados estão sendo compartilhados entre tarefas, o que pode ser útil para depuração ou auditoria.
- Limitações: É importante notar que o uso extensivo de XComs com dados de grande volume pode impactar o desempenho, pois eles são armazenados no banco de dados do Airflow. Além disso, deve-se ter cautela com a serialização de dados, garantindo que os dados possam ser devidamente codificados e decodificados.
- Práticas Recomendadas: Embora XComs sejam poderosos, é recomendado usar esse recurso com moderação e para o intercâmbio de dados leves, como identificadores, estados ou pequenos fragmentos de informações. Para o compartilhamento de grandes volumes de dados, outras abordagens, como armazenamento em sistemas de arquivos ou bancos de dados, podem ser mais apropriadas.
XComs são, portanto, uma ferramenta valiosa no Airflow, permitindo comunicação entre tarefas e adicionando uma camada de flexibilidade e interatividade aos fluxos de trabalho orquestrados.
Abaixo código de exemplo onde:
- ti (task instance) é um objeto que representa a instância da tarefa sendo executada
- xcom_push() é usada para definir o valor
- xcom_pull() é usada para recuperar o valor
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
dag = DAG('exemplo_xcom', description="xcom",
schedule_interval=None,start_date=datetime(2023,3,5),
catchup=False)
def task_write(**kwarg):
kwarg['ti'].xcom_push(key='valorxcom1',value=10200)
task1 = PythonOperator(task_id="tsk1",python_callable=task_write,dag=dag )
def task_read(**kwarg):
valor = kwarg['ti'].xcom_pull(key='valorxcom1')
print(f"Valor recuperado : {valor}")
task2 = PythonOperator(task_id="tsk2",python_callable=task_read,dag=dag )
task1 >> task2Explicação do código:
- Importações: As classes necessárias de Airflow e o módulo
datetimesão importadas. - Criação da DAG: Uma DAG chamada ‘exemplo_xcom’ é criada com
schedule_interval=None(indicando que a DAG não deve ser executada em um intervalo regular, mas apenas manualmente ou por meio de triggers externos),start_date=datetime(2023,3,5)(definindo a data de início) ecatchup=False(para evitar a execução de instâncias retroativas). - Definição de task_write: Esta função é um Python callable que usa
xcom_pushpara enviar um valor (neste caso,10200) associado a uma chave (‘valorxcom1’). O métodoxcom_pushé chamado no objetotask instance(ti), que é passado automaticamente para a função através do argumento**kwargs. - Criação de task1: Uma instância de
PythonOperatorchamadatask1é definida para executar a funçãotask_write. Quando esta tarefa é executada, ela armazena o valor10200com a chave ‘valorxcom1’ usando XCom. - Definição de task_read: Esta função recupera o valor armazenado pela
task1usandoxcom_pull, especificando a mesma chave (‘valorxcom1’). O valor recuperado é então impresso. - Criação de task2: Uma instância de
PythonOperatorchamadatask2é definida para executartask_read. Esta tarefa depende detask1e acessará o valor quetask1armazenou em XCom. - Definição de Dependência:
task1 >> task2estabelece quetask1deve ser concluída antes quetask2possa começar. Isso garante que o valor seja armazenado portask1antes quetask2tente recuperá-lo.
Variáveis
Variáveis no Apache Airflow são um recurso que permite armazenar, recuperar e gerenciar dados que podem ser usados em todo o seu ambiente Airflow. Diferentemente do XCom, que é usado para a troca de mensagens entre tarefas dentro de uma DAG, as variáveis são globais e podem ser acessadas por qualquer DAG dentro do ambiente Airflow. Aqui está uma visão geral sobre como as variáveis são utilizadas:
Armazenamento e Recuperação:
- Armazenamento Centralizado: As variáveis são armazenadas no banco de dados do Airflow, permitindo um ponto centralizado para gerenciar configurações, chaves de API, caminhos de arquivos, e outros dados que podem ser necessários em várias DAGs ou tarefas.
- Interface do Usuário: O Airflow fornece uma interface de usuário onde você pode adicionar, editar ou excluir variáveis facilmente.
- Acesso Programático: As variáveis podem ser acessadas programaticamente usando a classe
Variabledo Airflow em suas DAGs e tarefas.
Para usar uma variável em seu código, você primeiro precisa importar a classe Variable do Airflow:
from airflow.models import VariableDepois, você pode acessar o valor de uma variável usando o método Variable.get. Por exemplo, para recuperar o valor de uma variável chamada ‘my_variable’, você faria:
my_var_value = Variable.get("my_variable")Você também pode definir um valor padrão que será retornado caso a variável não exista:
my_var_value = Variable.get("my_variable", default_var="default_value")Em resumo, Variáveis permitem armazenar e compartilhar informações entre DAGs:
- Credenciais de API
- URLs
- Chaves de Autenticação
- Pode ser criadas na UI ou na CLI
Diferenças Variáveis VS XCom:
| Variáveis | XCom |
|---|---|
| Informações estáticas e globais | Informações dinâmicas |
| Usadas em todo o pipeline | Entre as tarefas |
Considerações:
- Segurança: Tenha cuidado ao armazenar informações sensíveis nas variáveis do Airflow. Embora existam maneiras de criptografar as variáveis, é importante garantir que o acesso ao Airflow seja devidamente controlado e monitorado.
- Performance: Acessar o banco de dados para recuperar variáveis pode introduzir latência. Portanto, é aconselhável usá-las com parcimônia e considerar o cache de valores quando apropriado.
- Manutenção: Manter um bom controle das variáveis que você cria e usa é essencial para evitar confusões e erros em suas DAGs. Nomeie suas variáveis de maneira clara e documente seu uso.
Pools
Os Pools no Apache Airflow são uma funcionalidade que permite limitar a quantidade de execuções paralelas de tarefas, baseando-se em recursos limitados disponíveis. Eles oferecem uma maneira eficaz de gerenciar e alocar recursos limitados dentro do ambiente Airflow para evitar sobrecarga do sistema ou exceder limites de uso externo, como APIs ou bancos de dados. Aqui está uma explicação detalhada sobre Pools no Airflow:
Finalidade dos Pools
Os Pools são utilizados para controlar a concorrência das tarefas executadas, especificamente quando há restrições de recursos. Eles garantem que o número de tarefas executando simultaneamente não exceda a capacidade disponível de recursos específicos. Isso é crucial em cenários onde múltiplas tarefas competem por um recurso limitado, como conexões de banco de dados, acessos a APIs com cotas de uso, ou recursos computacionais limitados.
Como Funcionam
Um Pool é definido por dois elementos principais: o nome do Pool e o número de “slots” que ele contém. Cada slot pode ser entendido como uma permissão para executar uma tarefa. Se um Pool tem 5 slots, isso significa que até 5 tarefas podem utilizar esse Pool simultaneamente. Se todas as permissões estiverem sendo utilizadas, tarefas adicionais que requerem acesso ao Pool serão colocadas em uma fila de espera até que um slot seja liberado.
Configuração e Uso
- Criação: Os Pools são criados no Airflow UI (Interface de Usuário) ou via código, onde você define um nome para o Pool e especifica o número de slots.
- Atribuição de Tarefas: Quando você define uma tarefa, pode especificar qual Pool ela deve usar através do argumento
pool. Isso garante que a tarefa só será executada se houver slots disponíveis no Pool especificado.
Monitoramento
O Airflow UI permite monitorar o uso dos Pools, mostrando quantos slots estão sendo utilizados e quantas tarefas estão em espera por um slot. Isso ajuda a identificar gargalos e a ajustar a configuração dos Pools conforme necessário.
Práticas Recomendadas
- Dimensionamento Adequado: É importante dimensionar os Pools adequadamente, baseando-se na capacidade dos recursos que eles representam e na demanda esperada de tarefas.
- Priorização: Em cenários onde múltiplas tarefas competem por slots em um Pool, considere atribuir prioridades às tarefas para garantir que tarefas críticas sejam executadas primeiro.
- Uso Consciente: Pools são ideais para gerenciar recursos limitados, mas seu uso indevido pode levar a ineficiências. Avalie outras formas de controle de concorrência e paralelismo oferecidas pelo Airflow, como limites de concorrência em DAGs e tarefas, para complementar o uso de Pools.
Exemplo código utilizando Pools:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
# Definição da DAG
dag = DAG(
'simple_pool_example',
start_date=datetime(2023, 3, 15),
schedule_interval=None,
catchup=False,
)
# Tarefa 1 usando o Pool
task1 = BashOperator(
task_id='echo_task1',
bash_command='echo "Task 1 is running"',
pool='example_pool', # Nome do seu Pool criado no Airflow UI
dag=dag,
)
# Tarefa 2 usando o mesmo Pool
task2 = BashOperator(
task_id='echo_task2',
bash_command='echo "Task 2 is running"',
pool='example_pool', # O mesmo Pool para limitar a execução paralela
dag=dag,
)Branchs
É a capacidade de executar diferentes tarefas com base em condições específicas durante o tempo de execução de uma DAG. Isso é realizado principalmente através do uso do operador BranchPythonOperator. Com o branching, você pode direcionar o fluxo de execução de sua DAG para diferentes caminhos, dependendo dos resultados de uma função Python ou de outras condições lógicas, tornando suas DAGs mais dinâmicas e flexíveis.
BranchPythonOperator
O BranchPythonOperator é um operador que permite a execução condicional de tarefas subsequentes. Ele decide qual caminho de tarefa seguir com base no valor retornado por uma função Python definida.
- Como Funciona: Você define uma função Python que contém a lógica de decisão (por exemplo, verificar o resultado de uma operação, valores de variáveis, data/hora, etc.). Essa função deve retornar o
task_idda tarefa que deve ser executada a seguir. - Implementação: O operador executa a função e segue o caminho determinado pelo
task_idretornado. Apenas a tarefa correspondente aotask_idretornado será executada, e todas as outras tarefas na bifurcação serão ignoradas.
Exemplo:
from airflow import DAG
from airflow.operators.python_operator import BranchPythonOperator, PythonOperator
from airflow.utils.dates import days_ago
from datetime import datetime
# Função para decidir qual caminho seguir
def decide_path():
# Aqui você define sua lógica, neste exemplo usaremos uma condição simples
if datetime.now().day % 2 == 0:
return 'par_day_task'
else:
return 'impar_day_task'
# Definindo a DAG
with DAG(
'simple_branching_example',
default_args={'start_date': days_ago(1)},
schedule_interval="@daily",
) as dag:
# Definindo o operador de branch
branch_task = BranchPythonOperator(
task_id='branch_task',
python_callable=decide_path,
)
# Tarefa para dias pares
par_day_task = PythonOperator(
task_id='par_day_task',
python_callable=lambda: print("Hoje é um dia par."),
)
# Tarefa para dias ímpares
impar_day_task = PythonOperator(
task_id='impar_day_task',
python_callable=lambda: print("Hoje é um dia ímpar."),
)
# Definindo a lógica de branching
branch_task >> [par_day_task, impar_day_task]- O
BranchPythonOperatoré usado para criar um ponto de bifurcação (branch_task) na DAG. A funçãodecide_pathverifica se o dia atual é par ou ímpar. - Baseado na decisão da função
decide_path, o fluxo de execução segue parapar_day_taskse o dia for par, ou paraimpar_day_taskse o dia for ímpar. - As tarefas
even_day_taskeodd_day_tasksão simples e apenas imprimem uma mensagem indicando se o dia é par ou ímpar.
Usos Comuns
- Decisões Baseadas em Dados: Tomar caminhos diferentes em uma DAG com base nos dados processados por tarefas anteriores.
- Gerenciamento de Fluxo de Trabalho: Habilitar ou desabilitar partes da DAG com base em critérios externos, como a disponibilidade de dados, resultados de operações anteriores ou configurações específicas.
- Experimentação e Testes: Facilitar a execução de experimentos controlados dentro de um fluxo de trabalho, onde diferentes branchs podem representar diferentes variantes de um experimento.
Datasets (Data-aware scheduling)
Funcionalidade que possibilita a criação de DAGs ligadas a arquivos, sejam eles armazenados localmente ou na nuvem, para iniciar processos de dados mediante a modificação de um ou mais arquivos, conhecidos como datasets.
Esses datasets são essenciais para solucionar a questão da dependência de dados entre diferentes DAGs. Tal situação ocorre quando uma DAG requer o consumo de dados provenientes de outra para análises ou processamentos subsequentes, permitindo, assim, a configuração de um agendamento mais eficaz e transparente, estabelecendo uma dependência clara entre as DAGs.
Existem dois princípios fundamentais nos Datasets do Airflow:
- DAG Producer: representa uma DAG responsável por gerar ou atualizar um ou vários datasets, utilizando um atributo denominado “outlets” em suas tarefas para especificar um dataset em particular.
- DAG Consumer: consiste em uma DAG que consome um ou mais datasets, sendo programada e ativada assim que os datasets necessários forem criados ou atualizados com sucesso pela DAG Producer. A programação é realizada diretamente nas configurações da DAG, por meio da opção “schedule”.
Atualmente, o Airflow oferece duas metodologias para programar DAGs: por meio de horários recorrentes (cron, timedelta, timetable, etc.) ou utilizando um ou mais datasets. É crucial notar que apenas um dos métodos pode ser aplicado em cada DAG.
Aspectos relevantes sobre Datasets
Os Datasets no Airflow são uma adição recente, com várias melhorias ainda pendentes por parte da comunidade. Contudo, vale ressaltar alguns aspectos atuais:
- A funcionalidade de Dataset do Airflow não analisa o conteúdo físico do arquivo, mas sim agenda a execução da pipeline consumidora através do banco de dados, funcionando como um gatilho implícito para a DAG.
- Levando em consideração o ponto acima, caso haja a necessidade de acessar o dado fisicamente no momento de ativar a DAG Consumer, o uso de um Sensor é recomendado.
- Apesar de a documentação oficial desaconselhar o uso de expressões regulares nas URIs dos Datasets, devido à não análise do arquivo físico pelo sistema, os testes realizados com expressões regulares não apresentaram problemas.
- Como a DAG Consumer não possui um agendamento próprio, é desafiador medir sua pontualidade, dificultando a definição de um SLA e exigindo um monitoramento mais detalhado para evitar perdas de agendamentos críticos.
A utilização da biblioteca DAG Factory facilita a criação e configuração de novas DAGs, beneficiando-se da flexibilidade oferecida pelo seu código aberto.
Os Datasets no Airflow possibilitam um agendamento de execução mais preciso, ativando DAGs somente quando os dados necessários estão disponíveis, minimizando execuções sem propósito e atrasos.
- Fontes: https://medium.com/data-hackers/agendamento-baseado-em-datasets-no-airflow-um-guia-pr%C3%A1tico-com-dag-factory-bccec99ecd1b
- https://airflow.apache.org/docs/apache-airflow/stable/authoring-and-scheduling/datasets.html
- https://docs.astronomer.io/learn/airflow-datasets?tab=taskflow#dataset-concepts
Sensors
Os Sensores no Apache Airflow são uma categoria específica de operadores usados para aguardar por um determinado evento ou condição antes de prosseguir com a execução das próximas tarefas em uma DAG. Eles são essenciais para orquestrar fluxos de trabalho que dependem da disponibilidade de dados, conclusão de tarefas em sistemas externos, ou qualquer outro evento externo. Aqui estão alguns pontos chave sobre os Sensores no Airflow:
Funcionamento dos Sensores
- Polling: Sensores geralmente operam por meio de polling, o que significa que eles verificam periodicamente a condição ou evento que estão aguardando. Se a condição ainda não foi atendida, o sensor irá dormir por um período configurável de tempo antes de verificar novamente.
- Sucesso: Quando a condição do sensor é satisfeita, ele permite que o fluxo de trabalho prossiga, passando o controle para a próxima tarefa na sequência da DAG.
- Timeout: Um sensor pode ser configurado com um timeout, o que significa que se a condição esperada não ocorrer dentro de um período de tempo especificado, o sensor falhará e, dependendo da configuração da DAG, isso pode fazer com que toda a DAG falhe ou execute um caminho alternativo.
Tipos Comuns de Sensores
- FileSensor: Aguarda até que um determinado arquivo esteja presente em um sistema de arquivos.
- HttpSensor: Verifica a disponibilidade de um recurso HTTP, aguardando até que uma solicitação a um URL específico retorne uma resposta esperada.
- ExternalTaskSensor: Aguarda a conclusão de uma tarefa em outra DAG. Isso é útil para orquestrar dependências entre diferentes fluxos de trabalho.
- SqlSensor: Aguarda até que uma consulta SQL específica retorne um resultado esperado. É comumente usado para verificar a disponibilidade ou o estado dos dados em um banco de dados.
Práticas Recomendadas
- Evitar Longos Períodos de Polling: Sensores que aguardam por muito tempo podem consumir recursos do executor desnecessariamente. Considere usar mecanismos de gatilho ou notificação externa, se possível.
- Configurar o Modo de Ressarcimento: O Airflow 2.0 introduziu a opção de configurar sensores para serem executados em modo “ressarcimento” (
reschedule), o que permite que eles liberem o slot do worker enquanto aguardam, tornando o sistema mais eficiente. - Timeouts e Falhas: Configure timeouts apropriados e gerencie falhas de sensores de forma que não prejudiquem desnecessariamente a execução de toda a DAG.
Código Exemplo:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
from airflow.providers.http.sensors.http import HttpSensor
import requests
dag = DAG('httpsensor', description="httpsensor",
schedule_interval=None,start_date=datetime(2023,3,5),
catchup=False)
def query_api():
response = requests.get("https://api.publicapis.org/entries")
print(response.text)
check_api = HttpSensor(task_id="check_api",
http_conn_id='connection',
endpoint='entries',
poke_interval=5,
timeout=20,
dag=dag)
process_data = PythonOperator(task_id="process_data", python_callable=query_api, dag=dag)
check_api >> process_dataEste código cria uma DAG no Airflow para primeiro verificar a disponibilidade de uma API externa usando um HttpSensor e, depois, processar os dados dessa API com um PythonOperator. Aqui estão os passos principais:
- Definição da DAG: Uma DAG chamada ‘httpsensor’ é configurada para não ter um agendamento fixo (
schedule_interval=None) e para não executar instâncias passadas (catchup=False), começando em 5 de março de 2023. - HttpSensor (
check_api): Verifica se a API emhttps://api.publicapis.org/entriesestá disponível, tentando a cada 5 segundos (poke_interval=5) por até 20 segundos (timeout=20). - PythonOperator (
process_data): Se a API estiver disponível, executa uma função (query_api) que faz uma requisição GET para a mesma API e imprime a resposta. - Dependência:
check_api >> process_dataestabelece queprocess_datasó executa apóscheck_apiconfirmar a disponibilidade da API.
Este fluxo garante que os dados só serão processados se a API estiver disponível, evitando erros devido à indisponibilidade do serviço externo.
Em suma, os Sensors são uma ferramenta poderosa no Airflow para garantir que as tarefas sejam executadas com base na disponibilidade de dados ou na conclusão de eventos, tornando seus fluxos de trabalho mais inteligentes e responsivos às condições do ambiente.
DAG que executa DAG
Executar uma DAG dentro de outra DAG no Apache Airflow, conhecido como DAG de subordinação ou “Sub-DAG”, é um padrão de design que permite encapsular e modularizar partes complexas de um fluxo de trabalho dentro de uma DAG maior. Essa abordagem pode ajudar a organizar melhor os fluxos de trabalho, tornando-os mais compreensíveis e gerenciáveis. Aqui estão os pontos principais sobre essa prática:
- Organização: Sub-DAGs são úteis para agrupar tarefas logicamente relacionadas, simplificando a DAG principal e tornando-a mais fácil de entender e manter.
- Reusabilidade: Sub-DAGs permitem a reutilização de fluxos de trabalho comuns em várias DAGs, evitando a duplicação de código e facilitando a manutenção.
- Isolamento: Executar uma DAG dentro de outra permite isolar partes do fluxo de trabalho, o que pode ser útil para depuração e teste, além de ajudar na organização lógica.
- Execução: Uma Sub-DAG é tratada como uma tarefa dentro da DAG principal. Quando a tarefa da Sub-DAG é executada, ela dispara a execução de todas as tarefas dentro da Sub-DAG.
- Monitoramento: Na interface do usuário do Airflow, a Sub-DAG aparece como uma única tarefa na DAG principal, mas você pode expandir e visualizar os detalhes e o progresso de suas tarefas internas.
No entanto, é importante notar que o uso de Sub-DAGs pode introduzir complexidade adicional e possíveis problemas de desempenho se não for bem gerenciado. Além disso, em algumas situações, pode ser mais apropriado considerar alternativas, como o uso de Task Groups ou diferentes DAGs coordenadas por meio de sensores ou triggers externos, dependendo dos requisitos específicos do fluxo de trabalho.
Abaixo um exemplo simples de uma DAG que executa DAG:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
from airflow.operators.dagrun_operator import TriggerDagRunOperator
dag = DAG('dagrundag1', description="Dag run dag",
schedule_interval=None,start_date=datetime(2023,3,5),
catchup=False)
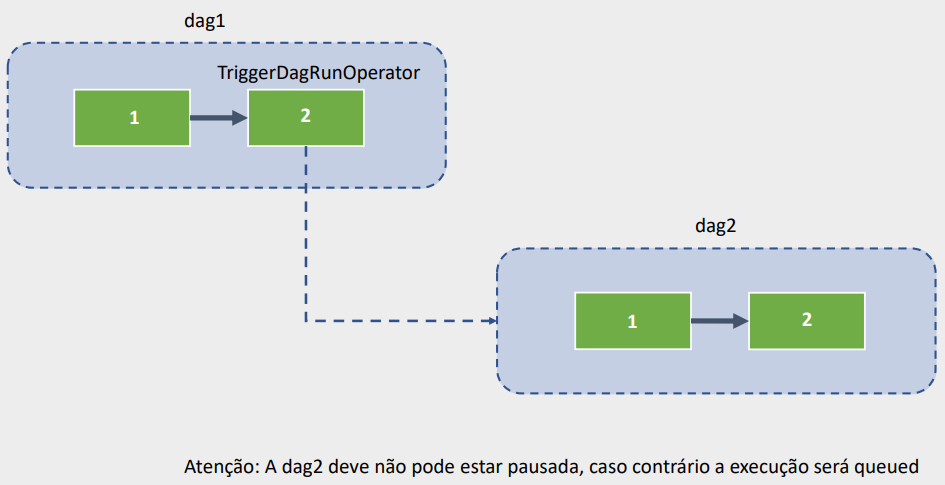
task1 = BashOperator(task_id="tsk1",bash_command="sleep 5",dag=dag )
task2 = TriggerDagRunOperator(task_id="tsk2", trigger_dag_id="dagrundag2" ,dag=dag )
task1 >> task2Explicação do Código:
- Importações: O código começa importando as classes necessárias do Airflow e o módulo
datetime. - Criação da DAG ‘dagrundag1’: Uma DAG é definida com o identificador ‘dagrundag1’, uma descrição, sem um intervalo de agendamento específico (
schedule_interval=None), uma data de início (start_date=datetime(2023,3,5)) e sem execução retroativa (catchup=False). - Definição da Tarefa
task1: Uma tarefa chamada ‘tsk1’ é criada usandoBashOperator, configurada para executar o comandosleep 5. Essa tarefa pausa a execução por 5 segundos, servindo como uma etapa preliminar antes de acionar a outra DAG. - Definição da Tarefa
task2: Uma tarefa chamada ‘tsk2’ é criada usandoTriggerDagRunOperator. Esta tarefa é responsável por acionar a execução de outra DAG, identificada aqui portrigger_dag_id="dagrundag2". Isso significa que, ao concluir atask1, atask2iniciará automaticamente a execução da DAG chamada ‘dagrundag2’. - Definição de Dependência: A linha
task1 >> task2estabelece uma dependência entre as duas tarefas, indicando quetask2(e, portanto, a execução de ‘dagrundag2’) só deve ocorrer após a conclusão bem-sucedida detask1.
Em resumo, este script define uma sequência de operações dentro da DAG ‘dagrundag1’, onde inicialmente pausa a execução por 5 segundos e, em seguida, automaticamente aciona a execução de outra DAG chamada ‘dagrundag2’. Esse padrão é útil para fluxos de trabalho que requerem a execução sequencial ou condicional de múltiplas DAGs baseadas em eventos ou resultados de tarefas anteriores.
Envio de E-mail
O Apache Airflow oferece recursos robustos para o envio de e-mails, permitindo que os usuários sejam notificados sobre o sucesso, falha, ou outras condições significativas das tarefas ou DAGs. Isso pode ser extremamente útil para monitoramento, alertas e integração com outras equipes ou sistemas. Aqui está uma visão geral de como o envio de e-mail funciona no Airflow:
Configuração SMTP:
Para enviar e-mails, o Airflow precisa ser configurado com as credenciais e configurações do servidor SMTP. Isso é feito no arquivo airflow.cfg:
- smtp_host: O endereço do servidor SMTP.
- smtp_starttls: Se deve usar TLS (geralmente definido como True).
- smtp_ssl: Se deve usar SSL (definido como False se você estiver usando TLS).
- smtp_user: O nome de usuário para autenticação no servidor SMTP.
- smtp_password: A senha para autenticação no servidor SMTP.
- smtp_port: A porta do servidor SMTP.
- smtp_mail_from: O endereço de e-mail do remetente padrão.
Uso em DAGs e Tarefas:
- Email em nível de DAG: Você pode configurar uma DAG para enviar e-mails em certas condições usando argumentos como
email_on_failureeemail_on_retry, e especificar os destinatários comemail. Esses argumentos podem ser incluídos nosdefault_argsda DAG. - Email Operators: O Airflow inclui operadores específicos para enviar e-mails, como o
EmailOperator. Com ele, você pode definir tarefas cuja única função é enviar um e-mail com conteúdo personalizado.
Exemplo de Uso do EmailOperator:
from airflow import DAG
from airflow.operators.email_operator import EmailOperator
from datetime import datetime
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 3, 5),
'email': ['your_email@example.com'],
'email_on_failure': True,
}
dag = DAG('email_example',
default_args=default_args,
description="An example DAG to send emails",
schedule_interval=None,
catchup=False)
send_email = EmailOperator(
task_id='send_email',
to='receiver_email@example.com',
subject='Airflow Alert',
html_content="""<h3>Email Test</h3>""",
dag=dag,
)
send_emailNeste exemplo, o EmailOperator é usado para criar uma tarefa que envia um e-mail quando executada. O conteúdo do e-mail é especificado em HTML, permitindo uma certa personalização da mensagem.
Considerações:
- É importante monitorar o uso do recurso de e-mail para não sobrecarregar os destinatários com notificações.
- Certifique-se de que as configurações de SMTP estejam corretas e seguras.
- O uso eficaz de e-mails no Airflow pode melhorar significativamente a gestão e a resposta a eventos importantes em seus fluxos de trabalho de dados.
Hooks
Hooks no Apache Airflow são interfaces para sistemas externos e serviços, fornecendo uma camada de abstração que permite aos usuários interagir com esses sistemas de forma mais simples e padronizada. Eles são projetados para encapsular detalhes de conexão e operações básicas, como ler e escrever dados, executar comandos ou consultar APIs, sem a necessidade de escrever código específico do sistema para cada interação.
Principais Características dos Hooks:
- Abstração: Os Hooks oferecem uma maneira abstrata de interagir com diversos sistemas externos, como bancos de dados (MySQL, PostgreSQL, MongoDB), serviços de armazenamento de arquivos (S3, GCP Cloud Storage), serviços de mensagens (Apache Kafka, RabbitMQ) e muitos outros.
- Reutilização: Eles permitem a reutilização de código para operações comuns, reduzindo a duplicação e facilitando a manutenção do código.
- Gerenciamento de Conexões: Os Hooks gerenciam conexões com sistemas externos, incluindo detalhes como credenciais, parâmetros de conexão e sessões. Isso é especialmente útil para garantir práticas seguras e eficientes de gerenciamento de conexões.
- Extensibilidade: O Airflow permite a criação de Hooks personalizados, possibilitando a extensão da plataforma para suportar novos sistemas ou serviços não cobertos pelos Hooks padrão.
Uso de Hooks:
Os Hooks são frequentemente utilizados em conjunto com Operadores, que executam tarefas específicas dentro de uma DAG. Enquanto um Operador define o que fazer, um Hook define como fazer em termos de interação com um sistema externo. Por exemplo, um PythonOperator pode usar um Hook para buscar dados de um banco de dados SQL antes de realizar alguma transformação de dados.
Exemplo Básico de um Hook:
Aqui está um exemplo simplificado de como um Hook pode ser usado em um script Airflow para se conectar a um banco de dados PostgreSQL e executar uma consulta SQL:
from airflow.hooks.postgres_hook import PostgresHook
from airflow.models import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def query_data():
# Cria uma instância do Hook
pg_hook = PostgresHook(postgres_conn_id="postgres_default")
# Usa o Hook para estabelecer a conexão e executar uma consulta
connection = pg_hook.get_conn()
cursor = connection.cursor()
cursor.execute("SELECT * FROM minha_tabela")
records = cursor.fetchall()
for row in records:
print(row)
with DAG('hook_example', start_date=datetime(2023, 3, 15), schedule_interval="@daily") as dag:
task = PythonOperator(
task_id="query_data",
python_callable=query_data
)Neste exemplo, o PostgresHook é usado para se conectar a um banco de dados PostgreSQL usando uma conexão previamente definida no Airflow (postgres_default). A função query_data então executa uma consulta SQL para buscar todos os registros de uma tabela e imprimi-los.
Executors
No Apache Airflow, Executors são componentes responsáveis por gerenciar a execução de tarefas dentro de uma DAG. Eles definem como as tarefas são executadas, seja de forma sequencial, em paralelo, em diferentes máquinas ou até mesmo em clusters de computação distribuída. A escolha do executor adequado é crucial para o desempenho e a eficiência dos fluxos de trabalho orquestrados pelo Airflow.
Tipos Principais de Executors no Airflow:
- SequentialExecutor:
- É o executor padrão que acompanha a instalação básica do Airflow.
- Executa uma tarefa por vez de forma sequencial e é adequado para desenvolvimento e testes, mas não é recomendado para produção devido à sua limitação de execução paralela.
- LocalExecutor:
- Permite a execução paralela de tarefas em um único servidor.
- As tarefas são executadas em processos separados, permitindo o aproveitamento eficaz de CPUs multi-core.
- É uma boa escolha para instalações de pequena a média escala que não exigem um ambiente distribuído.
- CeleryExecutor:
- Permite a execução distribuída de tarefas em múltiplos servidores usando o Celery, uma fila de tarefas distribuída focada em operações em tempo real.
- Suporta escalabilidade horizontal, adicionando mais workers conforme necessário.
- É ideal para ambientes de produção de média a grande escala, oferecendo robustez e flexibilidade.
- KubernetesExecutor:
- Integra o Airflow com o Kubernetes, permitindo que cada tarefa seja executada em um contêiner Docker separado dentro de um cluster Kubernetes.
- Oferece alta escalabilidade e isolamento de tarefas, sendo uma excelente escolha para ambientes dinâmicos e de grande escala.
- Suporta configurações dinâmicas, onde os recursos de execução podem ser ajustados para cada tarefa individualmente.
- DaskExecutor:
- Permite a execução distribuída de tarefas usando o Dask, um framework Python para computação paralela e distribuída.
- É uma opção para quem já utiliza o Dask para tarefas de processamento de dados paralelos e deseja integrá-lo com o Airflow.
Escolhendo o Executor Certo:
A escolha do executor depende de vários fatores, incluindo a escala de operação, a infraestrutura disponível, a necessidade de execução paralela ou distribuída, e considerações de orçamento. Enquanto o LocalExecutor pode ser suficiente para muitas instalações menores, ambientes de produção em larga escala podem se beneficiar significativamente da escalabilidade e flexibilidade oferecidas pelos CeleryExecutor ou KubernetesExecutor.
Configuração:
O executor é configurado no arquivo airflow.cfg do Airflow, onde você pode especificar o executor desejado. Mudar o executor pode exigir configurações adicionais, como a definição de uma fila de tarefas para o CeleryExecutor ou a configuração de um cluster Kubernetes para o KubernetesExecutor.
Executors são fundamentais para a operação do Airflow, pois determinam como as tarefas são executadas, afetando diretamente o desempenho, a eficiência e a escalabilidade dos fluxos de trabalho de dados.
Melhores Práticas
- Mantenha seus DAGs idempotentes, ou seja, uma execução repetida do DAG deve produzir o mesmo resultado.
- Teste seus DAGs localmente antes de movê-los para um ambiente de produção.
- Use conexões e variáveis do Airflow para gerenciar informações sensíveis.
- catchup=False.
- Otimize a Paralelização.
- Retries.
- Cuide de Erros.
- Gere Alertas.
- Use pools e defina prioridades.
O Airflow foi desenvolvido para workflows em lotes finitos. Embora a CLI e a API REST permitam o acionamento de workflows, o Airflow não foi criado para executar workflows baseados em eventos infinitamente. Airflow não é uma solução de streaming. No entanto, um sistema de streaming como o Apache Kafka é frequentemente visto trabalhando em conjunto com o Apache Airflow. O Kafka pode ser usado para ingestão e processamento em tempo real, os dados do evento são gravados em um local de armazenamento e o Airflow inicia periodicamente um workflow processando um lote de dados.
Se você preferir clicar e arrastar em vez de codificação, o Airflow provavelmente não é a solução certa. A interface da web visa tornar o gerenciamento de fluxos de trabalho o mais fácil possível e a estrutura do Airflow é continuamente aprimorada para tornar a experiência do desenvolvedor o mais tranquila possível. No entanto, a filosofia do Airflow é definir workflows como código, portanto a codificação sempre será necessária.
Conclusão
O Apache Airflow é uma plataforma poderosa e flexível para gerenciar fluxos de trabalho de dados complexos. Sua natureza open-source, extensibilidade e escalabilidade o tornam uma escolha popular para empresas de diversos setores.
Benefícios do Apache Airflow:
- Orquestração de fluxos de trabalho: O Airflow permite automatizar e agendar tarefas de maneira eficiente, garantindo que os dados sejam processados de acordo com as necessidades da empresa.
- Gerenciamento de dependências: O sistema de DAGs e operadores facilita a definição de dependências entre tarefas, garantindo a execução correta do fluxo de trabalho.
- Monitoramento e visualização: A interface web intuitiva do Airflow oferece aos usuários uma visão geral completa dos fluxos de trabalho em execução, permitindo a identificação e resolução de problemas de maneira rápida.
- Extensibilidade e escalabilidade: O Airflow é altamente extensível e pode ser adaptado às necessidades específicas de cada organização. A arquitetura modular facilita a integração com outros sistemas e ferramentas.
Considerações:
- Curva de aprendizado: O Airflow possui uma curva de aprendizado moderada. É necessário um conhecimento básico de Python e de conceitos de fluxo de trabalho para utilizá-lo de forma eficaz.
- Gerenciamento de infraestrutura: A execução do Airflow requer infraestrutura e recursos de computação. É importante considerar o dimensionamento e a segurança da infraestrutura ao utilizar a plataforma.
Em resumo, o Apache Airflow é uma ferramenta poderosa e versátil para gerenciar fluxos de trabalho de dados. Sua capacidade de automatizar tarefas, gerenciar dependências e oferecer visibilidade e controle sobre os fluxos de trabalho o torna uma solução valiosa para empresas que buscam otimizar seus processos de dados.
Dúvidas, sugestões ou comentários, por favor deixe nos comentários mais abaixo, no fim da página.
Keywords: Introdução ao Air Flow; Apache Airflow Brasil; Orquestração de fluxo de trabalho workflow; Automatização de pipeline de dados; Gerenciamento de tarefas em Big Data; Airflow e ciência de dados; Monitoramento de fluxo de trabalho workflow; Aprenda os conceitos básicos do Apache Airflow; Descubra como automatizar e agendar tarefas de forma eficiente; Explore os recursos e funcionalidades da plataforma; Dê os primeiros passos na construção de pipelines de dados robustas; Guia básico do Airflow; Começando com Apache Airflow; Guia básico do Airflow; Primeiros passos no Airflow; Introdução prática ao Airflow; Fundamentos do Apache Airflow; Airflow para iniciantes; Conceitos básicos do Airflow; Como configurar o Airflow; Airflow: O que é e como funciona; Introduzindo o gerenciamento de fluxo de trabalho com Airflow
Gostou do conteúdo? Quer receber mais dicas? Se inscreva ↗ grátis!
🔭Veja Também:
Siga nas redes sociais:
- Recuperação Dados Problema Trigger SDI Hana Enterprise [Data Architect Journal #1📜]
 Bem Vindo! | Welcome! By Felipe Lamounier, Minas Gerais, Brasil🇧🇷 – powered by 🙂My Easy B.I. 📑 Table of Contents: Contexto Definição do Problema e Objetivo Estratégia de Recuperação Dados Perdidos A estratégia de fazer o Script visa ser uma estratégia que será transparente para os sistemas que consome dados do Hana Enterprise XSA, comoContinuar lendo “Recuperação Dados Problema Trigger SDI Hana Enterprise [Data Architect Journal #1📜]”
Bem Vindo! | Welcome! By Felipe Lamounier, Minas Gerais, Brasil🇧🇷 – powered by 🙂My Easy B.I. 📑 Table of Contents: Contexto Definição do Problema e Objetivo Estratégia de Recuperação Dados Perdidos A estratégia de fazer o Script visa ser uma estratégia que será transparente para os sistemas que consome dados do Hana Enterprise XSA, comoContinuar lendo “Recuperação Dados Problema Trigger SDI Hana Enterprise [Data Architect Journal #1📜]” - Busca Avançada no Windows Explorer: Guia Completo
 Este artigo explora métodos avançados de pesquisa no Windows File Explorer. Abrange tópicos como indexação do Windows, operadores de pesquisa e exemplos de pesquisas complexas usando modificação de data, criação, extensão de arquivo e muito mais. Ao dominar essas técnicas, os usuários podem melhorar suas habilidades de pesquisa e encontrar arquivos e pastas com mais precisão.
Este artigo explora métodos avançados de pesquisa no Windows File Explorer. Abrange tópicos como indexação do Windows, operadores de pesquisa e exemplos de pesquisas complexas usando modificação de data, criação, extensão de arquivo e muito mais. Ao dominar essas técnicas, os usuários podem melhorar suas habilidades de pesquisa e encontrar arquivos e pastas com mais precisão. - Introdução ao Apache Airflow – Um Guia Básico
 Este post é uma rápida introdução ao Apache Airflow, uma ferramenta de orquestração de carga para programar, organizar e monitorar fluxos de trabalho complexos. Com a utilização do conceito de “DAGs” (Directed Acyclic Graphs), o Airflow permite que engenheiros de dados e desenvolvedores definam, automatizem e monitorem pipelines de dados de forma flexível e escalável. Através de uma interface de usuário intuitiva, extensibilidade através de plugins e a capacidade de integrar-se com uma ampla variedade de sistemas e serviços, o Airflow se tornou uma ferramenta essencial para orquestração de tarefas em ambientes de dados modernos, suportando desde simples tarefas de transferência de dados até workflows analíticos complexos.
Este post é uma rápida introdução ao Apache Airflow, uma ferramenta de orquestração de carga para programar, organizar e monitorar fluxos de trabalho complexos. Com a utilização do conceito de “DAGs” (Directed Acyclic Graphs), o Airflow permite que engenheiros de dados e desenvolvedores definam, automatizem e monitorem pipelines de dados de forma flexível e escalável. Através de uma interface de usuário intuitiva, extensibilidade através de plugins e a capacidade de integrar-se com uma ampla variedade de sistemas e serviços, o Airflow se tornou uma ferramenta essencial para orquestração de tarefas em ambientes de dados modernos, suportando desde simples tarefas de transferência de dados até workflows analíticos complexos.
